На сайте LF Energy опубликован материал, обобщающий выступление представителя RTE на конференции LF Energy Summit Europe. В докладе подробно рассказано, как французский оператор магистральных электрических сетей применяет открытую платформу SEAPATH для виртуализации систем релейной защиты, автоматики и управления (РЗА и АСУ ТП). Ниже — обзор ключевых тезисов с пояснениями для русскоязычного читателя.
От «коробочных» решений к интероперабельной архитектуре
Доклад начался с краткой истории подхода RTE к организации систем РЗА и АСУ ТП. С 2000 по 2020 год подстанции строились по принципу «под ключ»: каждый поставщик поставлял систему как единое целое. Даже при наличии общих спецификаций RTE реализации у разных вендоров расходились, а любые изменения в системе требовали раздельных контрактных согласований с каждым из них. Для оборудования, рассчитанного на эксплуатацию около 25 лет, такая модель оборачивалась ростом стоимости владения и снижением гибкости.
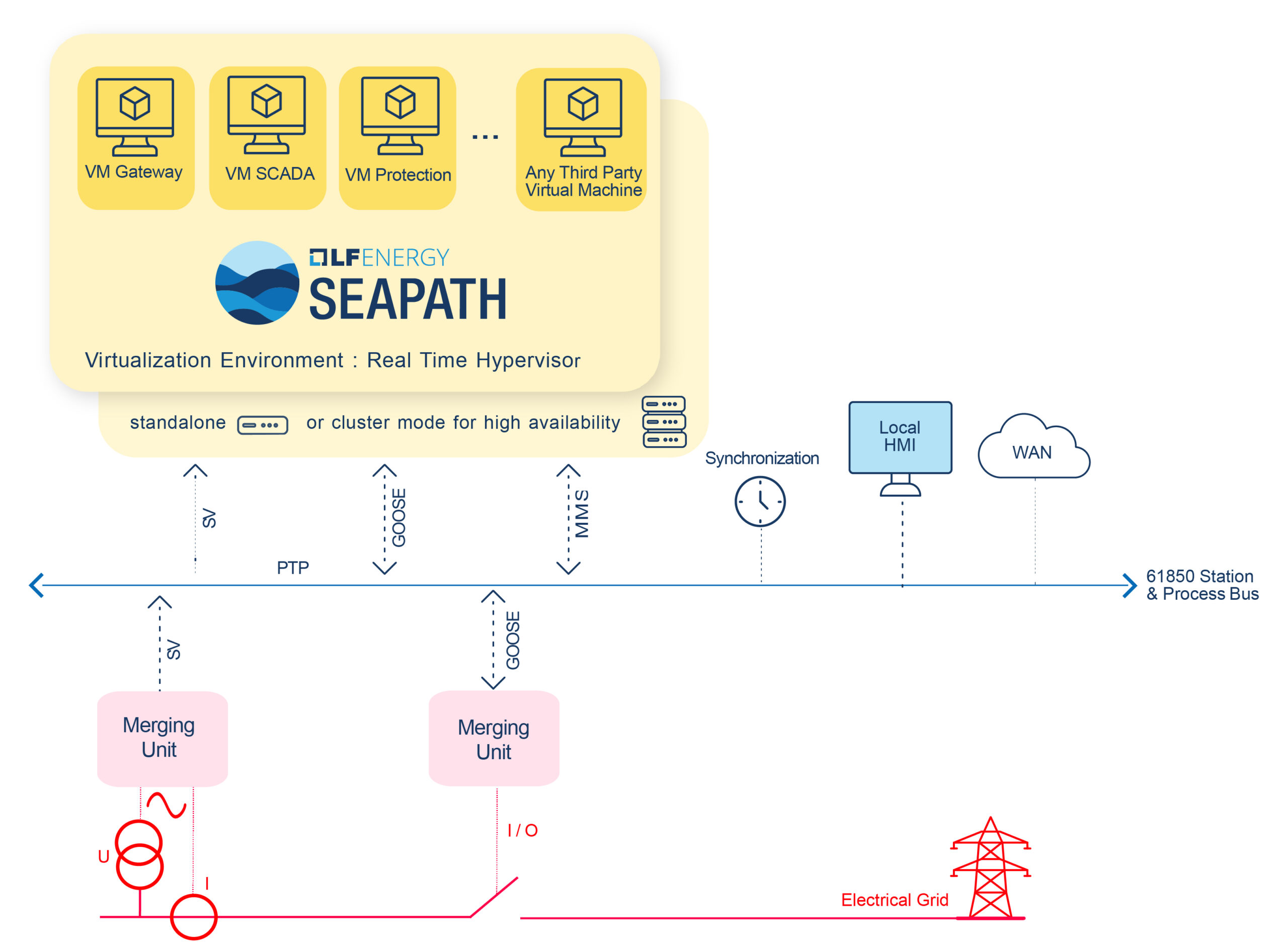
Текущая стратегия RTE — единая интероперабельная архитектура с возможностью применения оборудования разных производителей. Интеграцию RTE выполняет своими силами, а взаимодействие компонентов опирается на стандарты, прежде всего IEC 61850. В архитектуру добавляются серверы, на которых виртуализируется ключевая функциональность.
Почему открытый стек
При выборе подхода к виртуализации в RTE рассматривали три варианта: полный стек от одного поставщика, проприетарный слой виртуализации и стек на базе открытого кода. Выбран был третий вариант — на основе SEAPATH. Причины — сохранение прозрачности и контроля на уровне виртуализационного слоя и снижение зависимости от единственного вендора.
SEAPATH (Software Enabled Automation Platform and Artifacts Therein) — проект под зонтиком LF Energy, фонда Linux Foundation, развивающего открытое ПО для энергетики. Платформа распространяется под лицензией Apache 2.0 — пермиссивной и допускающей коммерциализацию — и позиционируется как security-hardened гипервизор реального времени для размещения vPAC-приложений (Virtualized Protection, Automation and Control) на цифровых подстанциях, поддерживающих IEC 61850. Среди заявленных встроенных возможностей — нативная поддержка синхронизации времени по NTP и PTP (IEEE 1588), что критично для шины процесса. Технологический стек, описанный в докладе RTE, включает дистрибутив на базе Debian, гипервизор KVM и инструменты автоматизированного развёртывания; в актуальном релизе SEAPATH 1.0 в проект также добавлена поддержка Yocto (открытый инструментарий для сборки собственных встраиваемых дистрибутивов Linux под конкретное железо и под конкретную задачу; не «готовая ОС, которую ставят», а «фабрика», на которой собирается ОС), а две ранее существовавшие ветки кода объединены в единую готовую к промышленной эксплуатации версию.
SEAPATH развивается не в изоляции, а как часть более широкой экосистемы открытых проектов LF Energy для цифровых подстанций. На уровне инструментария он интегрируется с CoMPAS — проектом для работы с конфигурациями систем РЗА и АСУ ТП в формате IEC 61850 SCL — и FledgePOWER, открытой IIoT-платформой для интеграции данных с подстанционного оборудования. Это означает, что виртуализация в SEAPATH не предполагает построения «параллельной» инженерной инфраструктуры — она встраивается в уже формирующийся открытый стек инструментов цифровой подстанции.
За проектом стоит представительный круг участников. Основные контрибьюторы — RTE, Alliander, GE Vernova, Savoir-faire Linux, Welotec и Red Hat. Технический руководящий комитет (TSC) формируется из представителей GE Vernova, RTE, Savoir-faire Linux, Schneider Electric и Welotec. Сочетание сетевых операторов, вендоров РЗА, поставщиков аппаратного обеспечения и сервисных компаний создаёт основу для устойчивого развития открытой кодовой базы и формирующейся вокруг неё экосистемы коммерческой поддержки.
Инженерная зрелость проекта подкреплена развитой инфраструктурой непрерывной интеграции: ежедневно прогоняется более 700 тестов, проверяющих, в частности, что виртуальные ИЭУ (vIED) укладываются в целевые показатели по задержкам, детерминизму и устойчивости. Проект разрабатывается с прицелом на применимость как в некритичных сценариях, так и в задачах, предъявляющих жёсткие требования реального времени.
Архитектура: гиперконвергентный кластер из трёх серверов
В рамках программы RSpace на каждой подстанции разворачивается кластер из трёх узлов, построенный по гиперконвергентной модели — на одних и тех же серверах общего назначения (COTS) одновременно работают слои вычислений, хранения и коммутации. По оценке сообщества SEAPATH, такая трёхузловая конфигурация заменяет около шести физических аппаратных устройств в традиционной архитектуре.
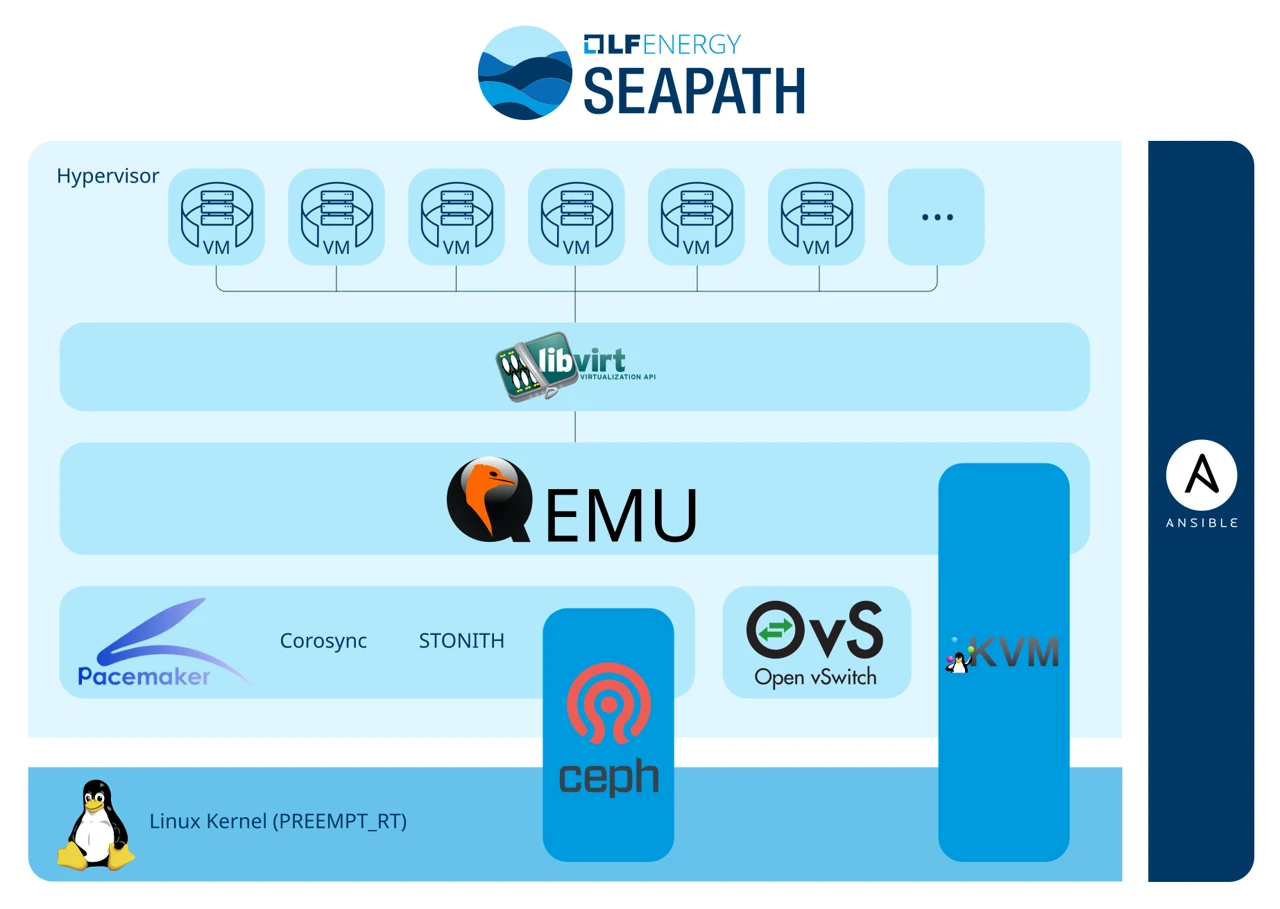
SEAPATH собран не как монолитный продукт, а как открытая референсная архитектура из зрелых компонентов экосистемы Linux. Каждый слой стека выполняет чётко определённую роль.
Гипервизор и слой исполнения виртуальных машин
В основе платформы — KVM (Kernel-based Virtual Machine), гипервизор первого типа, встроенный непосредственно в ядро Linux. KVM работает в связке с QEMU, обеспечивающим аппаратную виртуализацию и эмуляцию устройств для гостевых машин, и с libvirt — API/инструментарием управления гипервизором. Гипервизор устанавливается поверх ядра реального времени Linux (PREEMPT_RT), что обеспечивает детерминированное планирование и низкие задержки — обязательное условие для виртуальных ИЭУ (vIED), участвующих в обмене по IEC 61850-9-2 (Sampled Values), GOOSE и PTP.
В актуальной версии SEAPATH 1.0 поддерживаются две базовые сборки — на Debian и Yocto. Платформа разрабатывается как hardware-agnostic (работоспособна на x86 и ARM) и vendor-agnostic в отношении гостевых машин: на одном кластере одновременно могут работать виртуальные машины (ВМ) от разных поставщиков функций.
Кластеризация: Corosync, Pacemaker и фенсинг
Резервирование строится на классической связке Corosync + Pacemaker. Corosync отвечает за обмен сообщениями между узлами кластера и механизм heartbeat; Pacemaker управляет ресурсами кластера и принимает решения о перезапуске виртуальных машин на других узлах при отказах. Механизм STONITH (Shoot-The-Other-Node-In-The-Head) реализует фенсинг — гарантированную изоляцию проблемного узла, чтобы исключить «расщепление» данных. С точки зрения пользователя в каждый момент времени в кластере работает только один экземпляр каждой ВМ.
Распределённое хранение: Ceph
Образы дисков виртуальных машин и связанные с ними данные хранятся в Ceph — программно-определяемом распределённом хранилище. Ceph синхронно реплицирует данные между узлами кластера, и именно это позволяет ВМ быстро перезапускаться на сохранившемся узле при отказе одного из серверов: образ диска уже доступен локально, дополнительная синхронизация не требуется. Каждая ВМ хранится в Ceph как именованная RBD-группа.
Сколько узлов в кластере и почему именно три
Архитектура SEAPATH допускает работу как в standalone-режиме на одном сервере (без кластеризации, исключительно для собственно виртуализации), так и в виде кластера. Канонической для производственной эксплуатации — и применяемой RTE — является конфигурация из трёх узлов. Тройка здесь не маркетинговая, а инженерная.
Во-первых, кворум Corosync/Pacemaker требует большинства узлов для принятия решений о состоянии кластера и операций фенсинга. На двух узлах при потере связи между ними каждый считает выжившим себя — это классическая проблема split-brain, для которой нужны внешние арбитры. На трёх узлах при отказе одного оставшиеся двое сохраняют большинство и автономно продолжают работу.
Во-вторых, Ceph по умолчанию реплицирует данные с трёхкратным резервированием (size = 3): каждый блок хранится на трёх узлах. Это обеспечивает доступность и целостность данных при отказе любого одного узла без необходимости срочного восстановления.
Таким образом, три — это инженерный минимум для безопасной кластерной эксплуатации, а не предельная цифра. Ничто не препятствует строить кластеры из пяти и более узлов, если того требует масштаб подстанции, число виртуализируемых функций или политика резервирования.
Сетевая инфраструктура
С точки зрения сетей каждый узел кластера должен иметь как минимум три типа подключений:
- административная сеть для управления узлами;
- сеть для трафика IEC 61850 и PTP — основная «производственная» магистраль, через которую виртуальные машины общаются с устройствами сопряжения с объектом (merging units), GOOSE-абонентами и источником точного времени;
- внутренняя кластерная сеть, напрямую связывающая все три узла, — back-end для Ceph: синхронная репликация дискового трафика создаёт нагрузку, плохо совместимую с типовой подстанционной сетью, поэтому её выносят на отдельный канал.
Подключение виртуальных машин к шине процесса (SV) и шине станции (GOOSE/MMS) реализуется одним из трёх способов: через выделенный физический сетевой адаптер, проброшенный в ВМ напрямую (PCI passthrough); через виртуальные сети на базе OpenVSwitch и DPDK; или через SR-IOV-совместимые адаптеры, дающие каждой ВМ изолированную виртуальную функцию NIC. Конкретный выбор определяется требованиями к задержкам и совокупным числом нагрузок на узле.
Развёртывание и управление жизненным циклом
Развёртывание и конфигурирование SEAPATH построены по принципам Infrastructure as Code: декларативное описание желаемого состояния системы и автоматизированное приведение к нему через Ansible. Управление жизненным циклом ВМ — создание, клонирование, миграция, снимки, удаление — собрано в утилите vm_manager, Python-обёртке над Ceph, QEMU, libvirt и Corosync, скрывающей внутренние детали этих компонентов от инженера. В перспективе сообщество движется к загрузочному OCI-образу (bootc), в котором ядро реального времени, QEMU и Ceph поставляются единым атомарно обновляемым артефактом — это сократит роль Ansible на этапе конфигурации гипервизора и сделает обновления и откаты атомарными операциями.
Что виртуализируется на подстанциях RTE
В рамках программы RSpace в виртуальные машины вынесены:
- локальный АРМ оператора (HMI);
- шлюз / устройство связи с верхним уровнем (gateway / RTU);
- внутренние функции автоматики — например, логика УРОВ;
- FTP-службы для удалённого считывания регистраций аварийных событий;
- инструменты конфигурирования ИЭУ.
То есть на текущем этапе RTE выносит в виртуальные машины «верхнюю часть» системы — АСУ ТП, шлюзование, прикладную автоматику и инженерные сервисы — оставляя релейную защиту в физических устройствах. Изоляция, обеспечиваемая ядром реального времени, при этом позволяет одновременно размещать на одном узле и критичные, и некритичные нагрузки.
Доступность виртуальных машин: HA, CA и живая миграция
В дискуссиях о виртуализации часто смешивают три разные вещи. На самом деле они отвечают на разные вопросы: что мы делаем, когда что-то сломалось, чтобы оно вообще не было заметно, и зачем трогать работающую систему, если ничего не сломалось.
| Механизм | Когда срабатывает | Сколько простаивает пользователь | Аналогия |
|---|---|---|---|
| HA — high availability | сервер отказал | секунды – минуты (ВМ перезапускается на другом узле) | пробил колесо — остановился, поменял на запаску, поехал дальше |
| CA / FT — continuous availability / fault tolerance | сервер отказал | миллисекунды или ноль | у самолёта два двигателя — один отказал, второй уже работает |
| Live migration — живая миграция | планово, без отказа | доли секунды (отказа вообще нет) | пересели на ходу — машина не ломалась, просто захотели |
Теперь подробнее.
Высокая доступность (HA) — модель, при которой при отказе физического узла затронутые ВМ автоматически перезапускаются на другом узле кластера. Простой неизбежен: пока поднимется гостевая ОС и приложение, проходят секунды или десятки секунд. Именно эту модель реализует SEAPATH связкой Pacemaker (детектирует отказ и инициирует перезапуск) и Ceph (диск ВМ синхронно реплицирован на все узлы и сразу доступен на любом из них). Цифра около минуты на failover, которую называет RTE, — это и есть HA.
Непрерывная доступность / отказоустойчивость (CA / FT) — модель, при которой две копии одной ВМ постоянно работают параллельно на разных серверах и синхронизируют между собой состояния CPU и памяти. При отказе одного сервера второй продолжает обслуживание без потери состояния — клиентское приложение даже не заметит, что что-то случилось. Знакомый IT-инженерам пример — VMware Fault Tolerance. Цена — удвоенные вычислительные ресурсы и постоянная нагрузка на сеть для синхронизации.
Живая миграция (live migration) — это вообще не про отказы. Это плановый перенос работающей ВМ с одного узла на другой с минимальной паузой (доли секунды) — для техобслуживания сервера, перебалансировки нагрузки или вывода узла на регламент. Live migration штатно поддерживается KVM, а в SEAPATH доступна через утилиту vm_manager.
Для типичных «верхнеуровневых» функций подстанции — АРМ оператора, шлюзов, инженерных сервисов, медленной автоматики — модели HA вполне достаточно: минута простоя АРМ при отказе сервера приемлема, а на время планового обслуживания ВМ просто переезжают живой миграцией. CA в этом сегменте избыточен.
Для релейной защиты картина меняется кардинально: задержка в десятки миллисекунд — уже промах, минута — катастрофа. Поэтому при виртуализации защит обсуждается схема, концептуально аналогичная физическому миру с двумя реле в шкафу — «основная и резервная»: две независимые ВМ работают параллельно, обе принимают потоки SV и подписываются на GOOSE, и каждая принимает самостоятельные решения. Это, по сути, реализация принципа CA не на уровне гипервизора, а на уровне прикладной логики. Именно эту задачу — поставку алгоритмов защит в форме виртуальных машин, готовых к работе в такой схеме, — RTE сейчас и тестирует с двумя своими историческими партнёрами.
Из этого же следует и эксплуатационный плюс, который RTE отмечает уже на текущем этапе. Перенос «верхнеуровневых» функций в HA-режиме на кластер из трёх узлов распространяет резервирование на более широкий круг функций, чем разумно дублировать «железом», и одновременно повышает удалённую наблюдаемость системы. В RTE ожидают, что за счёт этого получится сократить число выездов персонала на объекты.
Не только RTE: экосистема внедрений
RTE — наиболее заметный, но не единственный пример работы с SEAPATH. Платформа развёрнута в тестовых средах GE Vernova, Alliander, ABB, Red Hat и Enedis. Французский DSO Enedis рассматривает SEAPATH как кандидата на роль виртуализационной среды для систем РЗА и АСУ ТП первичных подстанций. Schneider Electric параллельно ведёт собственные пилоты по виртуализации устройств, рассматривая её как шаг в сторону программно-определяемой архитектуры подстанции. GE Vernova использует SEAPATH как основу для собственных VPAC-пакетов и подтверждает, что развёрнутые прототипы способны удовлетворять жёстким требованиям реального времени.
Из крупных совместных инициатив отдельно стоит отметить сотрудничество National Grid Electricity Transmission (системный оператор Великобритании) и GE Vernova: компании объявили о совместной работе на базе SEAPATH для развития виртуализированных систем защиты и управления. Это уже второй после RTE случай, когда SEAPATH становится опорной платформой в проектах крупного TSO.
Сам RTE, по словам Максима Пеллетье, констатирует: первая подстанция на SEAPATH работает в эксплуатации уже больше года, и компания развёртывает новые объекты, расширяя при этом перечень виртуализируемых функций. Позиция оператора прямолинейна — SEAPATH рассматривается как способ для TSO и DSO в полной мере получить от виртуализации то, ради чего она затевалась: гибкость, экономическую эффективность и контроль над собственной системой РЗА и АСУ ТП.
Текущий статус и планы
На момент выступления в новой архитектуре работали три подстанции RTE; развёртывание планируется продолжать. Следующий рассматриваемый шаг — виртуализация функций релейной защиты. RTE объявил тендер среди исторических партнёров с вопросом, могут ли алгоритмы РЗ поставляться в виде виртуальных машин. На сегодня идут испытания с двумя поставщиками; завершение работ запланировано на следующий год.
Порог входа: что нужно, чтобы попробовать SEAPATH
Один из неочевидных, но содержательно важных аспектов проекта — он действительно открыт для самостоятельной проверки, и порог входа значительно ниже того, что подсказывает слово «подстанция».
К одной машине-гипервизору в документации предъявляются всего четыре требования: архитектура x86_64, поддержка аппаратной виртуализации (Intel VT-x или AMD-V), UEFI вместо legacy BIOS и IOMMU (Intel VT-d или AMD SVM-D). Это требования, которым удовлетворяет, по сути, любой современный ПК. Для производственной эксплуатации рекомендуется сервер, сертифицированный по IEC 61850; для оценочного развёртывания достаточно обычного офисного сервера или даже настольного ПК.
Дальше — выбор между двумя сценариями:
- Standalone — один гипервизор. Без кластеризации и отказоустойчивости, но это полноценная виртуализационная среда: можно поднять ВМ и поэкспериментировать с прикладной нагрузкой. Подходит для лабораторных стендов и проверки отдельных функций.
- Кластер — три машины: либо три равноправных гипервизора, либо два гипервизора и один observer-узел. Observer не выполняет собственно виртуализацию, но участвует в кворуме — это вариант сокращения стоимости. На каждом гипервизоре рекомендуется иметь два физических диска (один — под систему, второй — под Ceph). Узлы соединяются между собой тремя Ethernet-кабелями для внутрикластерной сети.
Сам процесс развёртывания построен по принципу «прочитал — повторил». Документация SEAPATH описывает четыре шага quick start: установка SEAPATH (с выбором между сборкой на Debian и сборкой на Yocto), коммутация и подключение машин, конфигурирование через Ansible-плейбуки и развёртывание первой виртуальной машины. Образы, Ansible-инвентари и сопутствующие инструменты доступны в репозиториях проекта на GitHub под лицензией Apache 2.0.
Иными словами, для оценки SEAPATH не нужно ни специализированного «подстанционного» железа, ни лицензий, ни договоров с поставщиком. Один настольный ПК с современным Intel/AMD CPU и базовым опытом администрирования Linux — и можно собрать стенд, на котором корректно работают KVM, libvirt и Ansible-обвязка SEAPATH. Три таких машины — и поднимается полноценный HA-кластер с Pacemaker и Ceph, на котором можно проверить, как ведёт себя failover. Для полноценной сцены IEC 61850 потребуется дополнительно как минимум программный merging unit или симулятор шины процесса, но это уже отдельная задача.
Для отрасли смысл этого прост: точка входа в эксперименты с виртуализацией РЗА и АСУ ТП существенно сместилась. Раньше «попробовать виртуализацию подстанции» означало договориться о стенде с системным интегратором или дождаться корпоративной программы — сейчас это вечер на чтение документации и развёртывание стенда на собственном железе.
Открытые вопросы
Среди сложностей в RTE выделяют три направления:
- интеграцию между компонентами разных производителей;
- управление зависимостью на уровне ПО — vendor lock-in при таком подходе смещается с уровня устройства на уровень приложения, но не исчезает;
- долгосрочную поддерживаемость стека: серверов, инфраструктуры виртуализации и прикладных функций на горизонте, сопоставимом с жизненным циклом подстанции.
Что это значит для отрасли
Опыт RTE — один из немногих публично описанных примеров, когда крупный системный оператор последовательно строит производственную эксплуатацию РЗА и АСУ ТП поверх открытого виртуализационного стека. Но за пределами RTE вокруг SEAPATH уже сложилась экосистема: проект поддерживается ведущими вендорами оборудования и сервисов, проходит испытания у нескольких сетевых компаний и доведён до релиза, заявленного как готовый к промышленной эксплуатации. На фоне многолетней дискуссии о возможности и целесообразности виртуализации функций цифровой подстанции это смещает разговор из плоскости «получится ли» в плоскость «как именно» — какие функции вынести в виртуальную среду в первую очередь, как организовать резервирование, как договариваться с вендорами защит о поставке алгоритмов в виде ВМ.
Дальнейший интерес представляют детали реализации — в частности, как организовано взаимодействие виртуальных машин с шиной процесса IEC 61850-9-2 (Sampled Values) и шиной станции (GOOSE/MMS), какие требования к серверной платформе и сетевой инфраструктуре RTE предъявляет на этапе виртуализации защит и как будет распределяться ответственность за надёжность системы между поставщиком аппаратной платформы, разработчиком гипервизора и поставщиком прикладной функции защиты.