En IEC 61850, GOOSE se ha convertido en uno de los mecanismos clave para el intercambio rápido entre dispositivos electrónicos inteligentes. Es GOOSE el que permite a los IEDs de protección, dispositivos de automatización, controladores de bahía y otros IEDs intercambiarse eventos: actuaciones de protección, enclavamientos, posiciones de equipos de maniobra, comandos de disparo, etc.
Pero el GOOSE clásico tiene una limitación arquitectónica fundamental: es un mensaje de capa de enlace Ethernet. Funciona muy bien dentro de la red local de la subestación, pero no está pensado para ser enrutado a través de redes IP normales.
Cuando el intercambio debe organizarse no solo dentro de una subestación, sino entre objetos remotos del sistema eléctrico, surge la necesidad de otro mecanismo — Routable GOOSE, o R-GOOSE.
GOOSE clásico: rápido, local, dentro de la subestación
GOOSE trabaja según el modelo publisher/subscriber: un dispositivo publica el mensaje, y uno o varios dispositivos suscriptores lo utilizan.
Usos típicos de GOOSE:
- transmisión de señales de disparo;
- enclavamientos entre IEDs;
- lógicas de fallo de interruptor, protección de barras, transferencia automática;
- intercambio de posiciones de interruptores y seccionadores;
- y otros.
La principal ventaja de GOOSE es la alta velocidad y una «sobrecarga» de protocolo mínima. El mensaje se transmite directamente por Ethernet, a nivel L2. Eso hace a GOOSE cómodo para tareas en las que importan los milisegundos.
Pero esto es también su limitación: el GOOSE corriente no se enruta a través de redes IP. Su área natural de uso es la red tecnológica local de la subestación.
Por qué apareció R-GOOSE
A medida que las subestaciones digitales fueron evolucionando, quedó claro que este tipo de intercambio se necesita no solo dentro de un único objeto.
Aparecieron tareas en las que el mensaje debe ser entregado de un nodo del sistema eléctrico a otro, o simultáneamente a varios nodos remotos:
- disparo remoto / aceleración remota;
- enclavamientos entre instalaciones;
- esquemas especiales de protección (SPS);
- y otros.
Para estos escenarios el Ethernet local ya no basta. Hace falta poder transmitir eventos por redes IP, incluida la infraestructura WAN de la empresa eléctrica.
Es aquí donde aparece Routable GOOSE — GOOSE enrutable.
Qué es R-GOOSE
R-GOOSE es la evolución de la idea de GOOSE para redes IP. Si el GOOSE clásico opera a nivel Ethernet, R-GOOSE añade la posibilidad de transmitir por una infraestructura IP enrutable.
Simplificando:
GOOSE — para intercambio rápido dentro de la red local de la subestación. R-GOOSE — para intercambio por red IP entre objetos remotos.
En IEC 61850, las variantes enrutables de GOOSE y Sampled Values permiten usar el modelo publisher/subscriber no solo dentro de una única red local, sino en una infraestructura de red más amplia.
Importante: R-GOOSE no es «GOOSE que simplemente vuela más lejos». Es otro contorno de ingeniería: enrutamiento IP, multicast, latencia, jitter, QoS, tolerancia a fallos, ciberseguridad y gestión de claves.
Y qué es R-SV
Junto con R-GOOSE se considera un segundo perfil — Routable Sampled Values, o R-SV.
La lógica es parecida. Los Sampled Values corrientes se transmiten en una red local, por ejemplo por el process bus de una subestación digital. Pero algunas tareas exigen transmitir los datos a grandes distancias.
Ante todo, se refiere a tareas ligadas a mediciones sincrofasoriales y a funciones distribuidas de protección y automatización. Si GOOSE y R-GOOSE son ante todo eventos, entonces SV y R-SV son mediciones transmitidas periódicamente.
En otras palabras:
R-GOOSE — eventos enrutables. R-SV — datos de medición en flujo o periódicos, enrutables.
En la práctica, R-GOOSE se discute y se aplica notablemente con mayor frecuencia, porque hay más escenarios para la entrega remota de eventos — disparo remoto, enclavamientos, esquemas especiales de protección — y son más claros para las tareas aplicadas de protección y automatización.
Ejemplo 1. Disparo remoto en lugar de un esquema de seccionador-puesta a tierra
Uno de los escenarios ilustrativos de aplicación de R-GOOSE es la transmisión de un comando de disparo remoto en lugar del uso de un esquema con seccionador-puesta a tierra.
En esquemas tradicionales, en subestaciones derivadas o en algunas posiciones puede aplicarse un esquema con seccionador-puesta a tierra. Su tarea es crear un cortocircuito controlado para que la protección del lado de la alimentación vea con seguridad el defecto y desconecte la línea.
Este enfoque funciona, pero desde el punto de vista de ingeniería resulta bastante duro: para desconectar el tramo dañado, en realidad creamos un cortocircuito adicional en la red.
R-GOOSE permite abordar esta tarea de otra forma. En lugar de crear un cortocircuito artificial, se puede enviar una señal de disparo remoto al interruptor necesario o a un grupo de interruptores por una red enrutable.
Esto es especialmente importante en redes de distribución con creciente participación de generación distribuida. Durante un cortocircuito, el hueco de tensión afecta no solo al alimentador dañado, sino también a las posiciones vecinas. Cuanto más tiempo persista el defecto, mayor el riesgo de desconexión indeseada de consumidores sensibles o de objetos de generación distribuida.
Un disparo remoto rápido permite reducir la duración del hueco de tensión y disminuir el impacto del fallo en partes adyacentes de la red. Es decir, R-GOOSE aquí es interesante no como «un nuevo protocolo por el protocolo», sino como una forma de implementar una lógica de desconexión más limpia y rápida sin crear un cortocircuito adicional.
Ejemplo 2. Esquemas especiales de protección (SPS)
El segundo escenario importante son los esquemas especiales de protección.
Estos esquemas operan a menudo no dentro de una sola subestación, sino a nivel de un tramo de la red o de todo el sistema eléctrico. Para tomar la decisión pueden necesitar señales de diferentes puntos: estado de las líneas, sobrecargas, estado de la generación, posición de los interruptores, eventos de defecto, parámetros del régimen.
En tales tareas importa no solo recibir la señal, sino entregarla en un tiempo determinado. Si el evento ocurrió en un objeto y la acción de control debe ejecutarse en otro, el GOOSE local corriente ya no es suficiente.
R-GOOSE puede usarse como transporte para un intercambio rápido de eventos entre objetos de SPS. Por ejemplo:
- transmisión del hecho de desconexión de una línea;
- envío de un comando de deslastre de carga;
- envío de un comando de limitación de generación;
- disparo de una acción de control predefinida;
- intercambio de señales entre varios nodos de un esquema SPS.
En tales sistemas son especialmente importantes los requisitos de latencia, redundancia de canales, ciberseguridad y diagnóstico. No se puede decir simplemente: «el mensaje va por IP, así que todo funciona». Hay que demostrar que la red garantiza el tiempo de entrega requerido en régimen normal, en fallos y en conmutaciones de rutas.
Ejemplo 3. Mediciones sincrofasoriales
Otra área de aplicación de los perfiles enrutables de IEC 61850 es la transmisión de datos de mediciones sincrofasoriales.
Las mediciones sincrofasoriales son importantes para la monitorización distribuida, el análisis de estabilidad, el control de regímenes y la construcción de sistemas WAMS/WAMPAC. A diferencia de los mensajes que llevan información sobre eventos, estos datos se transmiten periódicamente y deben llevar una marca temporal precisa.
Desde el punto de vista de ingeniería hay una diferencia importante con respecto al disparo remoto o a los SPS. Para la monitorización, la propia latencia de entrega puede no ser tan crítica si cada valor tiene una marca temporal correcta. El sistema puede reunir los datos de diferentes dispositivos para el mismo instante y luego ejecutar el análisis.
Pero si los datos sincrofasoriales se usan no solo para monitorización, sino para automática de actuación rápida, la latencia vuelve a ser un parámetro crítico. En ese caso hay que considerar no solo la precisión del tiempo, sino también el tiempo de entrega, el jitter, las pérdidas de paquetes y el comportamiento del sistema ante la degradación de los canales de comunicación.
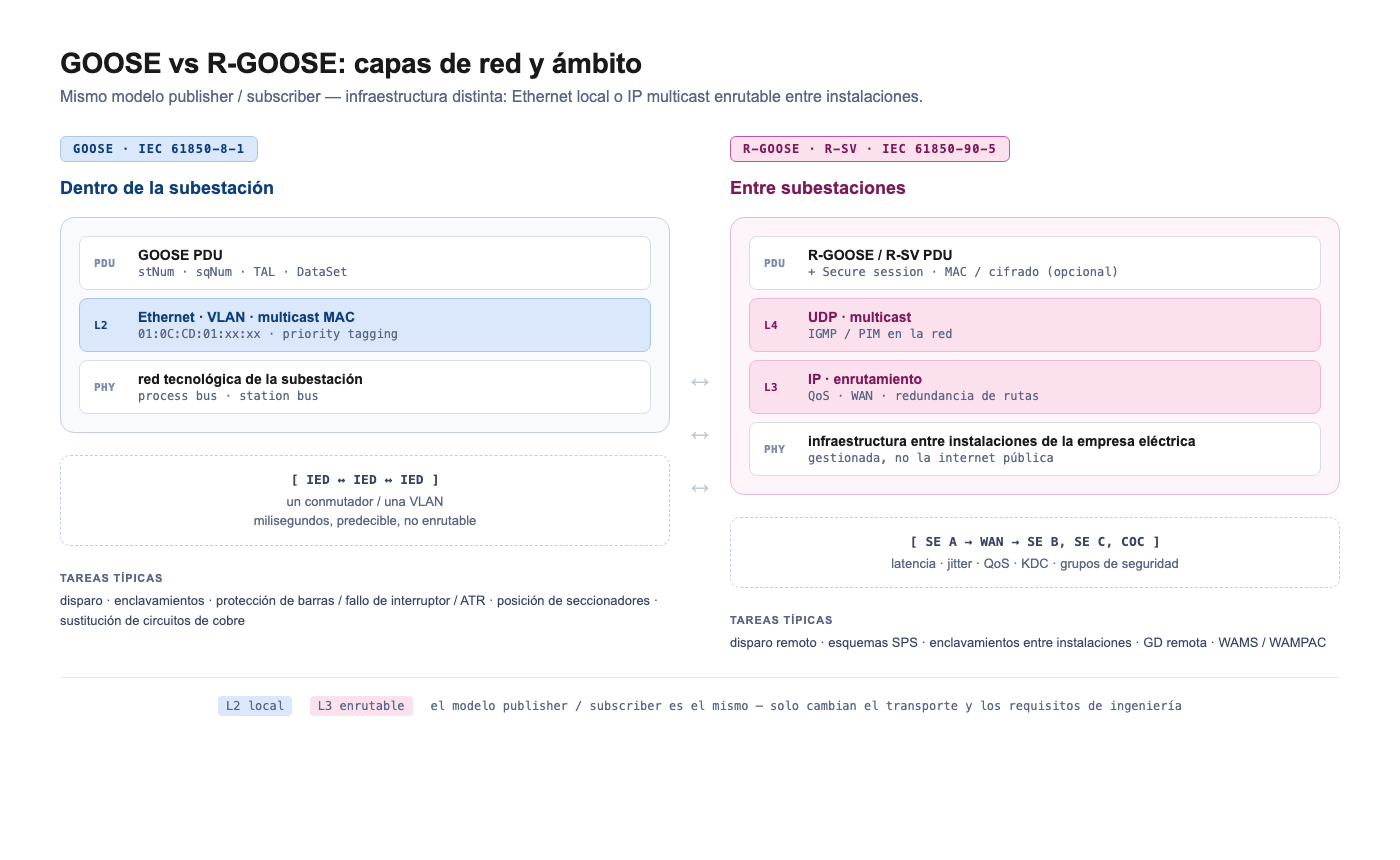
Capa de red: L2 vs L3
Desde el punto de vista de ingeniería, la principal diferencia entre GOOSE y R-GOOSE es la capa de red.
| Parámetro | GOOSE | R-GOOSE |
|---|---|---|
| Capa | Ethernet L2 | IP / UDP multicast |
| Ámbito | Red local de la subestación | Escenarios entre instalaciones y WAN |
| Enrutamiento | No | Sí |
| Modelo de intercambio | Publisher/subscriber | Publisher/subscriber por IP |
| Tareas típicas | Protección y automatización dentro de la SE | Disparo remoto, SPS, esquemas entre instalaciones |
| Principal riesgo | Errores de VLAN, multicast y suscripciones | Latencia, enrutamiento, seguridad, gestión de claves |
GOOSE es cómodo donde todo ocurre dentro de una única red tecnológica. R-GOOSE es necesario donde la función sale de los límites de una sola subestación y debe trabajar a través de una infraestructura enrutable.
Seguridad: por qué Secure R-GOOSE importa más que solo R-GOOSE
Cuando GOOSE permanece dentro de la red tecnológica aislada de la subestación, la seguridad sigue importando: VLAN, control de acceso, segmentación y otras medidas.
Pero cuando el mensaje sale de los límites de una subestación, la cuestión de la seguridad se vuelve central.
Para R-GOOSE y R-SV hay que tener en cuenta:
- la autenticación de la fuente del mensaje;
- la integridad de los datos;
- la protección contra suplantación;
- la protección contra reenvío de mensajes antiguos;
- la gestión de claves;
- la separación de zonas de red;
- los cortafuegos y las reglas de enrutamiento;
- la monitorización de anomalías;
- la verificación del comportamiento ante pérdida de comunicación y degradación del canal.
En la red local de la subestación, un GOOSE publicado por error ya puede causar consecuencias graves. En una red entre instalaciones, el coste del error es aún mayor: el mensaje puede disparar desconexiones, acciones de protección especial o cambios de régimen simultáneamente en varias instalaciones.
Por eso R-GOOSE no puede analizarse aparte de las cuestiones de ciberseguridad.
Por qué el multicast necesita un modelo de protección especial
Para la comunicación cliente-servidor clásica puede usarse el esquema habitual: cliente, servidor, TLS, certificados.
Pero GOOSE, R-GOOSE, SV y R-SV operan con otra lógica. Es publisher/subscriber y multicast. Un único mensaje puede estar destinado a varios suscriptores a la vez.
Por tanto, el modelo de seguridad también debe contemplar la comunicación en grupo. Hay que definir:
- quién tiene derecho a publicar el flujo;
- quién tiene derecho a recibirlo;
- qué dispositivos forman el grupo de suscriptores;
- cómo se distribuyen las claves;
- con qué frecuencia se renuevan;
- qué ocurre ante el compromiso de un dispositivo;
- cómo sacar a un dispositivo del grupo;
- cómo diagnosticar el fallo de suscripción por problemas de seguridad.
En sistemas grandes, sin gestión centralizada de claves, este esquema se vuelve rápidamente ingestionable. Por eso, para los perfiles enrutables seguros, la infraestructura de gestión de claves y de políticas de acceso desempeña un papel importante.
KDC: para qué se necesita en Secure R-GOOSE y Secure R-SV
Cuando hablamos de R-GOOSE y R-SV seguros, importa entender: no se trata solo del enrutamiento de mensajes por una red IP. Se trata de comunicación en grupo segura.
GOOSE, R-GOOSE, SV y R-SV trabajan según el modelo publisher/subscriber. Un dispositivo publica el flujo y varios dispositivos pueden ser sus suscriptores. Esto no es el esquema clásico «cliente — servidor», donde dos participantes establecen una conexión segura entre sí. Aquí una única fuente debe entregar el mensaje con seguridad a un grupo de receptores.
Por eso aparece el concepto de Security Group — grupo de seguridad. En él entran el publisher y todos los subscribers que tienen derecho a recibir un flujo concreto.
Por ejemplo, para un flujo Sampled Values ese grupo puede incluir:
- el dispositivo publicador, por ejemplo un merging unit (SAMU);
- todos los suscriptores que utilizan ese conjunto de mediciones;
- la infraestructura encargada de verificar a los participantes y emitir las claves.
Para R-GOOSE la lógica es la misma: al grupo pertenecen el dispositivo que publica el evento y todos los suscriptores que deben recibirlo y usarlo en su lógica.
Para que todos los participantes de ese grupo puedan verificar la autenticidad de los mensajes y, si hace falta, descifrarlos, necesitan una clave simétrica común. El dispositivo o función que distribuye esa clave entre los miembros del grupo se llama KDC — Key Distribution Center, es decir, centro de distribución de claves.
flowchart TB
subgraph PKI["Infraestructura de confianza"]
PKIICON["🏛️ PKI<br/>emisión y revocación de certificados"]
end
KDC["<b>🔐 KDC</b><br/><i>Key Distribution Center</i><br/>• verificación de certificados<br/>• política del grupo<br/>• emisión de claves simétricas<br/>• rotación (típicamente 24 h)<br/>• KDA — Key Delivery Assurance"]
PKIICON -. certificados .-> KDC
subgraph SG["Security Group · flujo R-GOOSE / R-SV"]
direction LR
PUB["<b>Publisher</b><br/>p. ej., MU / IED / controlador SPS"]
SUB1["Subscriber 1<br/>IED en SE remota"]
SUB2["Subscriber 2<br/>dispositivo SPS"]
SUB3["Subscriber N<br/>WAMS / centro de control"]
PUB ==>|"R-GOOSE / R-SV<br/>multicast"| SUB1
PUB ==>|" "| SUB2
PUB ==>|" "| SUB3
end
KDC -. "<b>PUSH</b><br/>rotación<br/>centralizada de clave" .-> PUB
KDC -. " " .-> SUB1
KDC -. " " .-> SUB2
KDC -. " " .-> SUB3
SUB1 -. "<b>PULL</b><br/>tras reinicio<br/>o desincronización" .-> KDC
NOTE["<b>Qué se entrega</b><br/>• clave actual<br/>• siguiente clave + hora de activación<br/>• política: algoritmo MAC, cifrado, periodo de rotación"]
KDC -.-> NOTE
style KDC fill:#FDE8E8,stroke:#F56C6C,color:#B71C1C
style PUB fill:#E3F2FD,stroke:#42A5F5,color:#0D47A1
style SUB1 fill:#E0F2F1,stroke:#26A69A,color:#004D40
style SUB2 fill:#E0F2F1,stroke:#26A69A,color:#004D40
style SUB3 fill:#E0F2F1,stroke:#26A69A,color:#004D40
style PKIICON fill:#FFF8E1,stroke:#E6A23C,color:#7A5418
style NOTE fill:#F4F6FB,stroke:#9aa6c8,color:#3a4566
Por qué se usa una clave simétrica
En R-GOOSE/R-SV seguros, la autenticación y el control de integridad del mensaje son obligatorios. La confidencialidad — es decir, el cifrado del contenido — puede aplicarse de forma adicional.
La autenticación se realiza calculando una firma criptográfica especial del mensaje — Message Authentication Code, o MAC. En algunas descripciones se utiliza el término HMAC, cuando la firma se construye sobre un algoritmo hash.
La lógica es:
- El publisher compone el mensaje.
- Sobre el contenido del mensaje se calcula un hash criptográfico.
- Ese hash se protege usando una clave simétrica.
- El receptor recibe el mensaje y recalcula el hash por las mismas reglas.
- Si el valor calculado coincide con el recibido, el mensaje se considera auténtico y no modificado.
Es decir, el suscriptor puede verificar que el mensaje realmente vino de un miembro del grupo y no fue manipulado por el camino.
Si se usa cifrado, el mismo material de clave del grupo protege la carga útil del mensaje. Importante: no se cifra el mensaje completo, sino justamente el payload, para que la infraestructura de red pueda procesar las cabeceras necesarias.
Qué hace exactamente el KDC
El KDC resuelve varias tareas.
Primero, comprueba si el dispositivo tiene derecho a ser miembro del grupo de seguridad. Para ello se usan certificados digitales. Los miembros del grupo y el propio KDC deben tener certificados de confianza, y la autenticidad del participante se verifica mediante una infraestructura de clave pública — PKI.
Segundo, el KDC emite claves simétricas a los miembros del grupo. Estas claves se necesitan para la autenticación de los mensajes y, si el cifrado está habilitado, para proteger la carga útil.
Tercero, el KDC gestiona la política de seguridad del grupo. La política puede definir:
- qué algoritmo MAC se usa para formar la firma criptográfica;
- qué algoritmo de cifrado se aplica, si el cifrado está habilitado;
- con qué frecuencia debe renovarse la clave;
- si se usa un mecanismo de confirmación de entrega de claves;
- cuándo debe entrar en vigor la nueva clave.
Cuarto, el KDC se encarga del cambio periódico de claves. Cuanto más tiempo se use una sola clave en el sistema, mayor el riesgo de compromiso. Por eso las claves deben renovarse regularmente. En las descripciones de los perfiles enrutables seguros se cita como periodo típico de rotación 24 horas. A la vez, a los miembros se les puede entregar la clave actual y la siguiente, lo que da margen para una conmutación segura.
PUSH y PULL: dos formas de entrega de claves
La entrega de claves del KDC a los miembros del grupo puede realizarse de dos formas: PULL y PUSH.
En el modo PULL el propio dispositivo solicita la clave al KDC. Esto se necesita, por ejemplo, al arranque del dispositivo, ante una desincronización de claves o si el dispositivo no pudo recibir correctamente la clave enviada previamente. Antes de emitir la clave, el KDC verifica el certificado del dispositivo y su derecho a pertenecer al grupo de seguridad correspondiente.
En el modo PUSH el propio KDC reparte la nueva clave a los miembros del grupo. Este modo es útil para actualizaciones centralizadas de claves, especialmente en grandes sistemas donde la gestión manual de claves se vuelve inviable.
En la práctica ambos mecanismos son importantes. PULL permite al dispositivo recuperarse tras un reinicio o problemas con claves. PUSH permite al KDC realizar de forma centralizada la rotación regular de claves para todo el grupo.
Key Delivery Assurance: por qué no basta con «cambiar la clave»
En un sistema TI corriente, un fallo en la actualización de la clave puede llevar a la pérdida de acceso al servicio. En el sistema eléctrico las consecuencias pueden ser mucho más graves: si parte de los dispositivos no recibió la nueva clave, pueden dejar de aceptar mensajes críticos de R-GOOSE o R-SV.
Para funciones de disparo remoto o esquemas especiales de protección esto es inadmisible. El cambio de claves no debe bloquear el funcionamiento de la función principal.
Por eso se aplica el mecanismo KDA — Key Delivery Assurance. Su sentido es que el KDC puede controlar el éxito de la entrega de la clave a los miembros del grupo. Si la nueva clave se entregó con éxito a un porcentaje definido de miembros, el KDC envía al publisher la información autorizadora, tras lo cual el publisher puede pasar a la nueva clave en el momento previsto.
En otras palabras, KDA sirve para que la rotación de claves no se convierta en causa de fallo de una función tecnológica.
Clave actual y siguiente
Detalle práctico importante: a los miembros se les pueden entregar dos claves a la vez — la actual y la siguiente.
Esto permite preparar los dispositivos por adelantado para el cambio de clave. En el mensaje se indica no solo la información de la clave actual, sino también el momento en que la siguiente clave debe activarse. Gracias a esto, publisher y subscribers pueden pasar de forma síncrona a la nueva clave sin ruptura de la comunicación segura.
Si los miembros disponen de la clave actual y de la siguiente, aparece un margen de tiempo que permite soportar una indisponibilidad temporal del KDC o un fallo de comunicación con él.
Qué ocurre ante la indisponibilidad del KDC
Una cuestión operativa muy importante: ¿qué pasa si el KDC queda temporalmente indisponible?
Para las funciones de ingeniería la respuesta no debe ser: «todo dejó de funcionar». Si R-GOOSE se usa para disparo remoto o para esquemas especiales de protección, una pérdida temporal de contacto con el KDC no debe bloquear de inmediato la transmisión y la recepción de los mensajes tecnológicos.
Precisamente por eso se aplica el esquema con claves entregadas por adelantado y con período de validez de las claves. Si los participantes ya tienen la clave actual y la siguiente, pueden seguir operando dentro de la política definida incluso durante una indisponibilidad breve del KDC.
Pero esto no significa que el KDC pueda considerarse un elemento secundario. Su fallo debe diagnosticarse, los eventos deben registrarse, y la operación debe entender:
- cuánto tiempo el sistema puede operar sin contacto con el KDC;
- qué grupos de seguridad ya disponen de la siguiente clave;
- qué dispositivos no recibieron la actualización;
- cuándo empezará el riesgo de perder la comunicación segura;
- cómo restaurar la sincronización de claves tras el retorno del KDC.
El KDC y el archivo SCL
Para el ingeniero de IEC 61850 importa que los grupos de seguridad no aparezcan de la nada. Los archivos SCL ya contienen información sobre los flujos, los vínculos publisher/subscriber, DataSet, Control Block, direccionamiento y suscripciones.
Sobre la base de estos datos se puede determinar qué dispositivos participan en un intercambio GOOSE, R-GOOSE, SV o R-SV concreto. En consecuencia, la información SCL puede usarse como base para formar grupos de seguridad y la política de acceso.
Este es un punto importante para la ingeniería y la operación: la seguridad de los perfiles enrutables debe ligarse al modelo de ingeniería del objeto, y no configurarse aparte «a mano» sin enlace con el proyecto SCD/SCL.
Si en el archivo SCD cambió la composición de los suscriptores, esto potencialmente afecta no solo al esquema de comunicación, sino también a la composición del grupo de seguridad. Por tanto, los cambios en el proyecto deben acompañarse de una revisión de las políticas del KDC y de los derechos de los participantes.
Qué debe verificar el ingeniero al implantar Secure R-GOOSE
Al implantar Secure R-GOOSE o Secure R-SV, el ingeniero debe verificar no solo el hecho del paso de los mensajes, sino toda la cadena de confianza y de gestión de claves.
Una checklist práctica puede ser así:
- están definidos el publisher y todos los subscribers para cada flujo seguro;
- para cada flujo está definido un Security Group;
- está claro qué certificados usan los dispositivos y el KDC;
- se ha probado el procedimiento de emisión, renovación y revocación de certificados;
- está definida la política del grupo: algoritmos, rotación de claves, necesidad de cifrado;
- se han probado los modos PUSH y PULL;
- se ha verificado que el dispositivo recibe la clave tras el reinicio;
- se ha verificado el funcionamiento durante la indisponibilidad temporal del KDC;
- se ha verificado el mecanismo de rotación de claves;
- se ha verificado que el cambio de clave no bloquea la función tecnológica;
- los eventos del KDC y los errores de claves están disponibles para diagnóstico;
- los cambios en el proyecto SCD/SCL están sincronizados con los grupos de seguridad.
Routable no significa internet pública
Que R-GOOSE y R-SV sean enrutables no significa que deban transmitirse por la internet pública no protegida.
R-GOOSE no es «GOOSE a través de internet». Es un mecanismo para una infraestructura IP gestionada, segura y dimensionada en ingeniería del sistema eléctrico.
Esta red debe garantizar:
- latencia previsible;
- redundancia;
- control de rutas;
- QoS;
- protección contra acceso no autorizado;
- diagnóstico;
- monitorización del estado de los canales;
- responsabilidad operativa clara.
Por eso la implantación de R-GOOSE no es solo tarea de protección, sino también de arquitectura de red, seguridad de la información y operación.
Latencia y rendimiento
Para el GOOSE local la métrica principal es el tiempo de entrega rápido y previsible dentro de la red tecnológica.
Para R-GOOSE los requisitos son más complejos. Además del tiempo de entrega del propio mensaje, aparecen:
- latencias de enrutamiento;
- procesamiento de multicast;
- funcionamiento de los canales WAN;
- redundancia;
- posible procesamiento criptográfico;
- comportamiento ante la degradación de la comunicación;
- tiempo de recuperación tras la conmutación de ruta.
Para tareas de monitorización parte de estas latencias puede ser admisible. Para disparo remoto y esquemas especiales de protección — no. Allí la latencia pasa a formar parte del tiempo total de actuación de la función.
Por eso, al diseñar R-GOOSE hay que empezar no por la pregunta «cómo transmitir el mensaje», sino por:
¿qué tiempo máximo de entrega es admisible para esta función?
Y solo después elegir la arquitectura de red, los mecanismos de redundancia, los requisitos a los canales y los medios de control.
Diferencia práctica para el ingeniero
Para el ingeniero de protección y SCADA la diferencia entre GOOSE y R-GOOSE puede formularse así:
GOOSE — es una tarea local en la subestación digital. R-GOOSE — es una tarea dentro del sistema eléctrico.
GOOSE exige entender:
- el archivo SCD;
- el GOOSE Control Block;
- el DataSet;
- VLAN y priority tagging;
- multicast MAC;
- los parámetros
stNum,sqNum,timeAllowedToLive; - los flags
test,simulation,ndsCom; - el comportamiento del suscriptor ante pérdida o modificación del mensaje;
- y otros.
R-GOOSE exige todo lo anterior más:
- direccionamiento y enrutamiento IP;
- UDP multicast;
- infraestructura de multicast;
- QoS y cálculo de latencias;
- redundancia WAN;
- gestión de claves;
- certificados y grupos de seguridad;
- diagnóstico de flujos seguros;
- y otros.
Dónde usar GOOSE y dónde R-GOOSE
flowchart TB
START["<b>¿Qué función estamos implementando?</b>"]
Q1{"¿La función sale<br/>de los límites<br/>de una subestación?"}
Q2{"¿Qué se transmite:<br/>evento o<br/>datos periódicos?"}
Q3{"¿Latencia admisible<br/>para la función<br/>aplicada?"}
GOOSE["<b>GOOSE</b><br/>Ethernet L2 · multicast<br/>VLAN · priority tagging<br/>SCD: GoCB · DataSet"]
RGOOSE["<b>R-GOOSE</b><br/>IP / UDP multicast<br/>+ Secure session, KDC<br/>SCD + arquitectura de red + ciberseguridad"]
RSV_MON["<b>R-SV (monitorización)</b><br/>mediciones sincrofasoriales<br/>WAMS / monitorización distribuida<br/>lo principal — marca temporal precisa"]
RSV_AUTO["<b>R-SV (automática)</b><br/>latencia, jitter,<br/>pérdidas — críticas<br/>la WAN se diseña aparte"]
START --> Q1
Q1 -- "no, local" --> GOOSE
Q1 -- "sí, entre instalaciones" --> Q2
Q2 -- "evento" --> RGOOSE
Q2 -- "mediciones periódicas" --> Q3
Q3 -- "monitorización (decenas–cientos de ms ok)" --> RSV_MON
Q3 -- "automática rápida" --> RSV_AUTO
NOTE1["⚠️ R-GOOSE / R-SV ≠ internet pública<br/>se requiere una infraestructura WAN gestionada<br/>con QoS, redundancia y control de rutas"]
RGOOSE -.-> NOTE1
RSV_MON -.-> NOTE1
RSV_AUTO -.-> NOTE1
style START fill:#E0F2F1,stroke:#26A69A,color:#004D40
style Q1 fill:#FFF8E1,stroke:#E6A23C,color:#7A5418
style Q2 fill:#FFF8E1,stroke:#E6A23C,color:#7A5418
style Q3 fill:#FFF8E1,stroke:#E6A23C,color:#7A5418
style GOOSE fill:#E3F2FD,stroke:#42A5F5,color:#0D47A1
style RGOOSE fill:#FBE9E7,stroke:#E64A19,color:#BF360C
style RSV_MON fill:#EDE7F6,stroke:#7E57C2,color:#311B92
style RSV_AUTO fill:#FDE8E8,stroke:#F56C6C,color:#B71C1C
style NOTE1 fill:#F4F6FB,stroke:#9aa6c8,color:#3a4566
El GOOSE corriente sigue siendo la solución óptima para funciones locales de la subestación:
- enclavamientos;
- desconexiones;
- señales de automatización;
- intercambio entre IEDs de protección;
- interacción entre dispositivos dentro de una única red tecnológica;
- sustitución de circuitos de cobre dentro del objeto.
R-GOOSE se necesita donde la función sale de los límites de una sola subestación:
- disparo remoto entre instalaciones;
- esquemas especiales de protección;
- transmisión de eventos entre subestaciones y centrales;
- interacción con objetos remotos de generación distribuida;
- lógica de control de régimen entre instalaciones.
R-SV puede ser de interés para tareas de transmisión de datos de medición a través de WAN, especialmente cuando se trata de mediciones sincrofasoriales y monitorización distribuida.
Qué cambia esto para la operación de las subestaciones digitales
Para la operación de las subestaciones digitales, la aparición de R-GOOSE y R-SV significa que la frontera de responsabilidad del ingeniero se amplía.
Antes bastaba con entender lo que ocurre dentro del bus de estación o del bus de proceso de una subestación. Ahora, para una serie de tareas, hay que entender también la red entre instalaciones:
- por qué enrutadores pasa el mensaje;
- cómo está construido el multicast;
- qué latencias son admisibles;
- dónde están el publisher y los subscribers;
- cómo está protegido el flujo;
- quién gestiona las claves;
- qué ocurrirá ante un fallo de canal;
- cómo se comportará el sistema ante degradación de la comunicación;
- cómo registrar y demostrar el funcionamiento correcto en ensayos.
Esto ya no es solo «subestación digital» en sentido estricto. Es la infraestructura digital de comunicación del sistema eléctrico.
Conclusión
GOOSE sigue siendo el mecanismo básico y eficiente para el intercambio rápido de eventos dentro de la subestación digital.
R-GOOSE extiende esa idea a las redes IP enrutables y permite construir funciones entre instalaciones: disparo remoto, esquemas especiales de protección, enclavamientos entre instalaciones y otros escenarios en los que un evento de un nodo debe llegar de forma rápida y segura a varios suscriptores remotos.
R-SV resuelve una tarea similar para mediciones, incluyendo escenarios ligados a mediciones sincrofasoriales y a monitorización distribuida.
Pero la conclusión principal es otra: R-GOOSE y R-SV no son solo «GOOSE y SV por IP». Son perfiles de comunicación enrutables seguros, que requieren una nueva disciplina de ingeniería: cálculo de latencias, diseño de multicast, gestión de claves, aplicación de mecanismos de ciberseguridad y verificación obligatoria del comportamiento del sistema en regímenes normales y de avería.
El KDC en esa arquitectura no es solo «un servidor de claves» en algún sitio de la red. Une entre sí el modelo de ingeniería IEC 61850, la composición de los grupos publisher/subscriber, los certificados digitales de los dispositivos, las claves simétricas, la política de rotación y la preparación operativa de la comunicación segura.
Por eso, al discutir R-GOOSE, lo importante no es la pregunta «¿se puede enviar GOOSE más lejos?», sino otra completamente distinta:
¿qué función estamos implementando, por qué red funciona, qué tiempo de entrega es admisible, cómo está protegido el flujo y qué ocurrirá ante un fallo de comunicación?
Solo después de responder a estas preguntas R-GOOSE deja de ser un término bonito de la norma y pasa a ser una herramienta de trabajo del sistema eléctrico digital.